The plan with Kanbo is to skip having priority fields for tasks and instead to just let the cards be rearranged in whatever order you like. This poses a couple of technical challenges: first, the only nice user interface for rearranging things is drag-and-drop, and second, relational databases are notoriously wedded to the idea that entities are an unordered set, so how should the order be represented?

Why Ordering > Priorities
A quick aside on why I think an ordered queue is important. There is the obvious one, which is that I want to represent a physical notice-board, and one attribute they have is you can rearrange the cards.
The other is that I think that the other approach, using a priority attribute for each task and letting the order of tasks emerge from that, will ultimately fail. You start out with something simple, like High, Medium, and Low priority, but soon you find that no tasks are Low and you need a new priority higher than High, and some tasks really are more important that Medium but should go after all the other High priority tasks. And no matter how often you discuss the distinction between important tasks and urgent tasks, there will be people muttering darkly when they discover that correcting the spelling of copyright message is higher priority than adding someone’s pet feature. Perhaps priority should be on a 1-to-10 scale? Or 0 to 100 in multiples of 10?
In the end it is simpler to leave scoring tasks out and concentrate on the end result: which task should be completed before which. The reasons for doing one thing before another may be importance or urgency or a vague idea of how long it will take, but that discussion happens during the planning meeting and does not need to be represented in Kanbo.
Note that I am talking here about priority used to decide which order to do things in, once it has been established that these tasks are to be done; there is another process that happens before Kanbo where you decide whether a task must, should, could, or won’t be done.
User Interface
One trouble with this is that drag-and-drop sorting has no simple analogy in the old-fashioned forms-based HTML. I want my app as much as possible to work on the principle of progressive enhancement, but this will inevitably be compromised when it comes to sorting lists.
In the end I do have a vestigial form-based system: you get a form in which you can enter the numbers of some cards to rearrange them so that those cards are in the order you specify. When the JavaScript code runs to activate the drag-and-drop version, it hides the forms. Though, to be honest, this is not really a useful solution to making the page work without JavaScript.
The sortable lists come as a ready-made user-interface behaviour from the jQuery UI project. They even have an option to make dragging between lists work automatically, which is just what I need to allow users to drag cards between columns to change states. Nifty!
I actually approached the JavaScript in two phases. The first activated the drag-and-drop feature, and when a card is dropped in a new position it filled in the aforementioned form, ready for me to click the button. The second phase switched to sending the information using an Ajax call.
In the Database
One common way to represent ordered items in a database is to add an extra field called weight or rank or whatever, and sort on that. This works well enough, but there is the problem that moving one item will require renumbering a large number of other items. With an SQL database this is not so bad: it can probably be done in a single command that updates all the entities at once, though there I wonder whether there will be concurrency issues with overlapping moves when the number of simultaneous users is high. It is tricky to represent this sort of query via the usual object–relational mapping—although you are free do do arbitrary SQL incantations, they make your models dependent on the SQL dialect spoken by your database. This would be a bigger deal we were using a non-relational database, where renumbering 1000 entities actually involved 1000 queries.
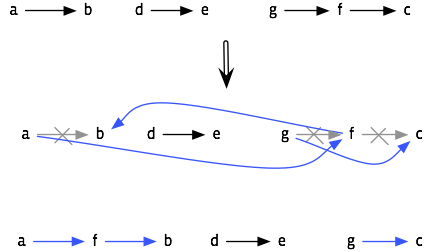
So this time I am trying a different approach. Instead of totally ordering the items with sequence numbers, we store a partial order in the database: each entity has an extra field that references to another entity that comes after it (this field can be null). While working out the algorithms, I wrote this with letters for stories and arrows showing the successor relationship:
a → b
g → f → c
d →e
Given a partial order, you can use a topological sort to come up with a total order for the stories:
a b d e g f c
The ordering represented in the database is so limited that the usual topological sort algorithm can be simplified quite a bit. Where there are several possible orders, the natural order of the entities (their creation order) is retained. (Cleverer algorithms may also be available.)
The point here is that a drag-and-drop rearrangement only needs to change at most three entities. For example, to take f and drop it in front of b , we need to change the successor field of a, f , and g (the predecessor of f):
In the (admittedly unlikely) high-contention scenario, this reduces the number of records locked at any one time, which reduces the probability of stuttering and delays because of conflicts.
The upshot of this is two functions in the models module: toposorted
takes a list of entities and returns a sorted copy, and rearrange_objects
takes a sequence of entities and rearranges the successor links to ensure that
the entities in that sequence are in that order. This generalizes the drag-
and-drop case to allow for moving more than one entity at a time. Whether this
is useful remains t be seen.
The web requests used by the JavaScript code correspond to the
rearrange_objects call.
Algorithms!
So there it is—I have an approach for storing sortable objects that seems to work well enough. It might be clever or it might be dumb, I’m never sure which. In either case you can look at the code in GitHub to see how it works or tell me where I have missed a corner case. Share and enjoy!
Update: 2012-04-16. The downside to this approach is that the sorting is happening in my app instead of in the database (both are running on the same VPS at present, so it makes little odds). My tester has revealed that if he adds enough stories (say, 20,000) he can make the sorting take so long the request times out, so some more work is obviously needed.